Using LLMs to fuzzy merge
Embeddings to the rescue!

TL;DR: Here is a public GitHub gist showing how to use OpenAI’s API to do fuzzy string matching in R.
Update: You can now use Melissa Dell’s LinkTransformer Python package do this for free, no OpenAI API key required. See the Python script in the public gist.
A few years ago, I collected some data that required a fuzzy merge with administrative data on schools. I’d never done a fuzzy merge before, and tried many different approaches, but ultimately couldn’t get over the hump.
You can even track this from my twitter feed:
But now it seems LLMs can make this process much, much easier.
LLM embeddings explained
An LLM embedding is a numerical representation of text data that captures the meaning and the context of the text. Essentially, it is an easy way to simultaneously reduce the dimensionality of a text string and convert it to a numeric format.
As OpenAI writes, this has many useful applications:
OpenAI’s text embeddings measure the relatedness of text strings. Embeddings are commonly used for:
Search (where results are ranked by relevance to a query string)
Clustering (where text strings are grouped by similarity)
Recommendations (where items with related text strings are recommended)
Anomaly detection (where outliers with little relatedness are identified)
Diversity measurement (where similarity distributions are analyzed)
Classification (where text strings are classified by their most similar label)
Utilizing OpenAI’s text embeddings
We can use OpenAI’s text embeddings in R or Python by signing up for an API key and using a package to communicate with the API. Calls to the API are extremely cheap; a collaborator of mine recently did about 45,000 calls for about 5¢. Our API calls involved very short snippets of text, so if you want to use it for longer text then the rate will be higher.
Example R script
I’ll walk through an R script below to illustrate how this works. In this example, I have two datasets that each have the name of a high school in the United States. However, the two datasets may have different naming styles for the schools (e.g. “Valley View HS” in one and “Valley View High School”). This makes exact merging impossible. But OpenAI’s text embeddings are astonishingly good at noting the similarity in exactly the way that a human would intuit.
Step 1: Load packages and Invoke API
library(tidyverse)
library(openai)
#------------------------------------------------------------------------------
# Step 1: Open AI API key
#------------------------------------------------------------------------------
# Your OpenAI API key should be an environment variable you set in ~.Renviron
# ... you should never put your API key directly in your code!There’s not much to say here other than that you should always store your API key in a way that it is invisible to whoever is reading the script.
Step 2: Cosine similarity
OpenAI suggests using cosine similarity to compare the embeddings of two strings. Here I provide two functions:
Compute the cosine similarity between any two embeddings
Find the maximum of the cosine similarity between one row of the primary dataset and every row of the secondary dataset. This is how we find the “best match.”
#------------------------------------------------------------------------------
# Step 2: Define functions for later use:
#------------------------------------------------------------------------------
# Function 1: calculate the cosine similarity between two vectors
cosine_similarity <- function(x, y) {
sum(x * y) / (sqrt(sum(x^2)) * sqrt(sum(y^2)))
}
# Function 2: compute the maximum cosine similarity and its index between a vector and a list of vectors
max_cosine_similarity_index <- function(x, y_list) {
# Use map_dbl() to compute the cosine similarity with each vector in y_list
cos_sim <- map_dbl(y_list, cosine_similarity, x = x)
# Return a list with the maximum value and its index of cosine similarity
list(max_cos_sim = max(cos_sim), max_cos_sim_index = which.max(cos_sim))
}The second function is best accomplished with the purrr package.
Step 3: Read in the data
Nothing too fancy here:
#------------------------------------------------------------------------------
# Step 3: Read in the data
#
# Assume you have two data frames called df1 and df2
# Each has a field with a school name
# For example: df1 has columns "id" and "HS"
# df2 has columns "schid" and "name"
#------------------------------------------------------------------------------
df1 <- read_csv("test1.csv")
print(df1)
df2 <- read_csv("test2.csv")
print(df2, n=100)Step 4: Obtain embeddings from OpenAI API
Here is where we get the embeddings using the create_embedding() function from the openai package. OpenAI recommends using the model “text-embedding-ada-002.” This costs 1/100¢ per 1,000 tokens. (As a reference, 1 token is about 4 characters in English.)
It does take quite some time to communicate with the API and get back the embeddings. For this simple example, it took about 5 minutes for the names of about 150 schools.
This code then stores in each row of the dataframe an embedding vector. Each embedding vector has hundreds of entries.
#------------------------------------------------------------------------------
# Step 4: Get the embeddings for the key in each dataset
#
# This may take some time (took about 5 minutes for about 130 API calls)
# Cost is $0.0001 / 1K tokens
#------------------------------------------------------------------------------
# Get the embeddings for the school names in df1 using the model text-embedding-ada-002
df1$embedding <- map(df1$HS, function(x) create_embedding(input = x, model = "text-embedding-ada-002")$data$embedding[[1]])
# Get the embeddings for the school names in df2 using the same model
df2$embedding <- map(df2$name, function(x) create_embedding(input = x, model = "text-embedding-ada-002")$data$embedding[[1]])Step 5: Do the fuzzy match
Now that we have the embeddings, we compute the cosine similarity between each row of the primary key in our dataframe of interest (df1 in this case) and each row in the dataframe we want to link with (df2 in this case). Then we match based on the element that has the greatest similarity.1
#------------------------------------------------------------------------------
# Step 5: For each primary key, find the maximally similar foreign key in the
# other dataset
#------------------------------------------------------------------------------
# Get the school name with the most similar embeddings
df1$similarity <- map(df1$embedding, max_cosine_similarity_index, y_list = df2$embedding) %>% map_dbl("max_cos_sim")
df1$argmax_similarity <- map(df1$embedding, max_cosine_similarity_index, y_list = df2$embedding) %>% map_int("max_cos_sim_index")
df1$matched_name <- df2$name[df1$argmax_similarity]Step 6: Inspect the matches
It’s always a good coding practice to manually inspect a random set of matches to ensure that things are working properly. Here’s what the matches look like in my sample data:
#------------------------------------------------------------------------------
# Step 6: Inspect match performance
#------------------------------------------------------------------------------
df1 %>% select(HS,matched_name,similarity) %>% print
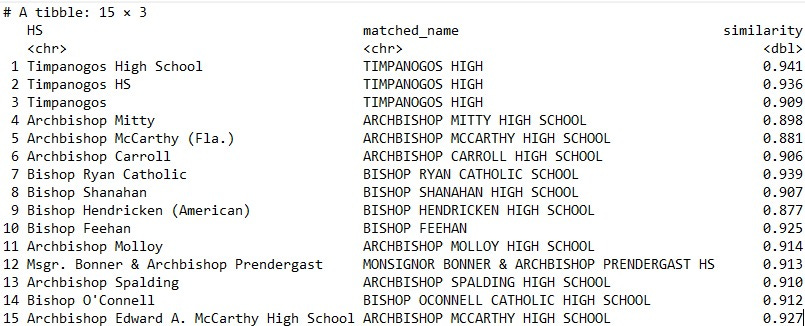
The embeddings for “Timpanogos High School” and “Timpanogos HS” were highly similar. Moreover, the embeddings worked well even though the name was in all caps in one dataset and proper capitalization in the other.
Note that it would be easy to modify the max_cosine_similarity_index() function to return the 2nd most similar, 3rd most similar, … Nth most similar elements. This should be a good idea in more complicated matching situations.
Currently working on linking schools for the Record Linking Lab. This is very helpful, thank you!
This is super useful thanks! I am thinking of an application to clean up an ID column in a single dataframe, in this case would you merge the dataframe with...itself?
```
import linktransformer as ltf
# load df
df = pd.read_csv(...)
ltf.merge(df, df, ... )
```